准备工作
- node >= 16
- ts-node
- eslint
- typescript
- cheerio
- @types/cheerio
- superagent
- @types/superagent
关于环境搭建不再赘述,可以翻看之前的文章
分析要抓取的网站
- 最好是服务端渲染的网站
- 客户端渲染的直接分析接口就行了,没有必要爬,因为也爬不到什么
- 下面以某美女网为例
首页分析
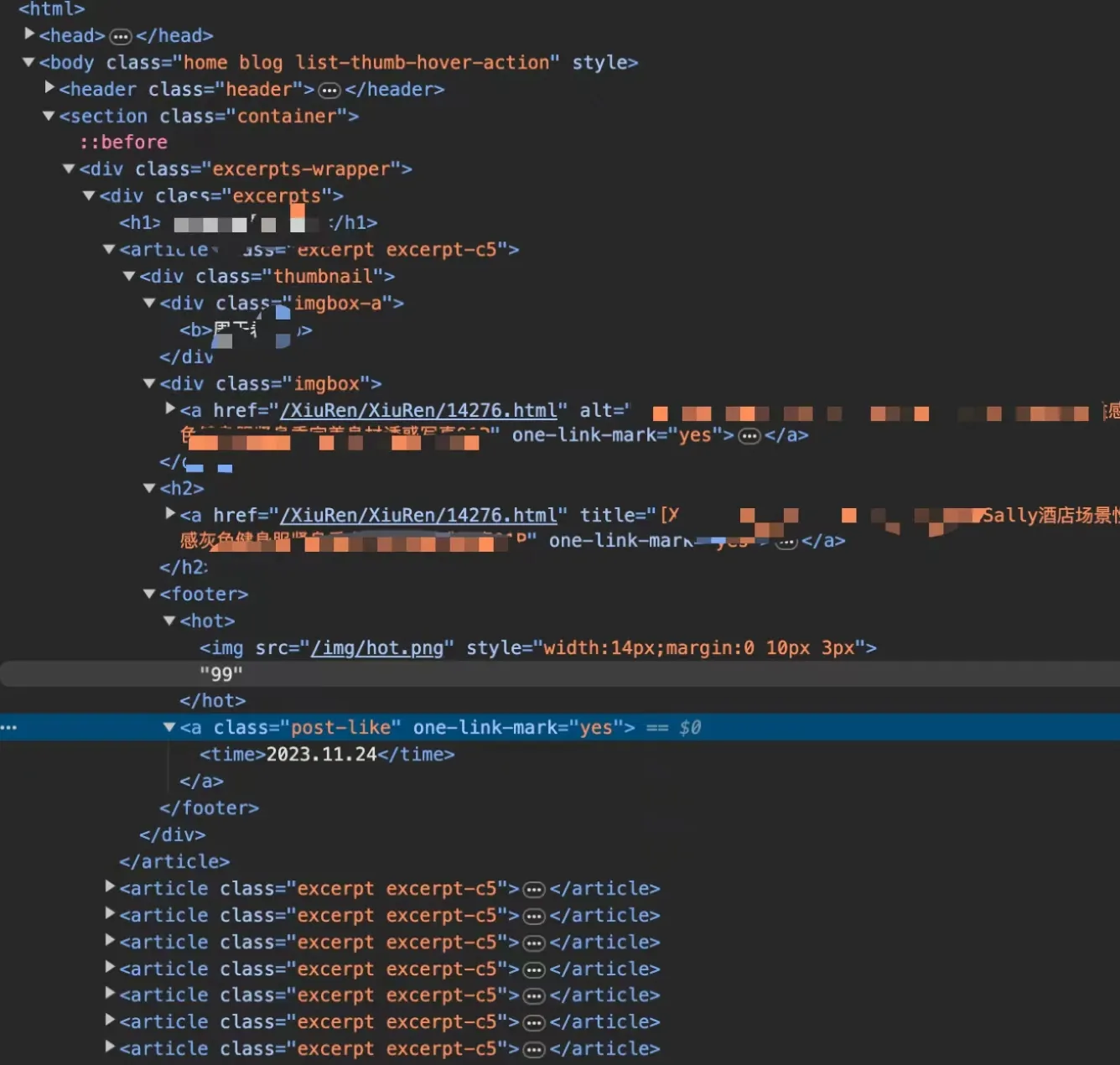
打开控制面板,通过选中元素可以发现
- 首页所有的美女都在excerpts元素下
- excerpt下就是每个美女图片的信息了
- 通过展开excerpt可以发现
- 姓名
- 封面图
- 子路径
- 发布日期
基础框架搭建
class Spider {
host = "https://***.net"; // 首页地址
getContent() {}
constructor() {
this.getContent();
}
}获取首页内容
import superAgent from "superagent";
class Spider {
host = "https://***.net"; // 首页地址
async getContent(uri: string = "") {
const response = await superAgent.get(this.host + uri);
return response.text;
}
constructor() {
this.getContent();
}
}通过superagent就可以获取到首页的网页内容了
获取所有美女信息
import superAgent from "superagent";
import cheerio from "cheerio";
interface Lady {
name: string;
uri: string;
poster: string;
publishDate: string;
}
class Spider {
host = "https://***.net"; // 首页地址
getLadies(html: string) {
const $ = cheerio.load(html);
const ladies = $(".excerpts").find(".excerpt");
const result: Lady[] = [];
ladies.map((index, element) => {
const name = $(element).find("b").text();
const uri = $(element).find(".imgbox").find("a").attr("href") as string;
const poster = $(element).find(".imgbox").find("a").find("img").attr("src") as string;
const publishDate = $(element).find("footer").find("a").find("time").text();
result.push({
name,
uri,
publishDate,
poster,
});
return null;
});
return result;
}
async getContent(uri: string = "") {
const response = await superAgent.get(this.host + uri);
// return response.text
const ladies = this.getLadies(response.text);
console.log(ladies);
}
constructor() {
this.getContent();
}
}- 这里我们通过cheerio可以像操作JQ一样操作dom
- 并且定义一个接口来规范存储的格式
- 运行
npx ts-node src/main.ts测试 - 顺利的话就得到了一个长度20的数组
子页分析
上面已经获取到了首页里所有的美女信息并装在了数组里,而通过host+uri的形式就可以进入到每个子页里,而这里才是我们要关注的重点,因为这里有着大量的素材图片,由于这个子页每次只能预览三张图片,而且还有点卡顿,所以我们要想办法一次性把所有的图片都给抓取出来